SISAP 2023 Indexing Challenge 参加記
松井研B4の小栗です。 類似度検索に関する国際会議であるSimilarity Search and Applications (SISAP 2023)にて開催された近似最近傍探索のコンペティションIndexing Challengeに参加しました。結果として、一部トラックで2位となることができました。加えて、コンペで用いた手法に関する論文がShort Paperとして採択されました。 今回はコンペの概要、参加した感想、そしてコンペで用いた手法についてお伝えします。
- 論文: Yutaro Oguri and Yusuke Matsui, “General and Practical Tuning Method for Off-the-Shelf Graph-Based Index: SISAP Indexing Challenge Report by Team UTokyo”
- 実装: Submission by Team UTokyo
近似最近傍探索とは
近似最近傍探索(Approximate Nearest Neighbor Search, ANNS)とは、ベクトルの集合の中からクエリベクトルに最も近いベクトルを高速に検索する近似アルゴリズムです。Faissなどの著名なライブラリに実装されています。 近年では深層学習モデルで埋め込みベクトルに変換した文書を検索したり、LLMの知識補完の検索部分に用いたりといった用途があります。以前からSIFTといった画像特徴量ベクトルに対して適用する研究は盛んに行われてきましたが、近年のこれらの発展により、より広い用途でANNSが使われています。
ANNSの近年の著しい発展については松井先生のスライドをご覧ください。
今回対象にするグラフベースのindexは、メモリに載る限りでは他のタイプのindexよりもパフォーマンスに優れています。このindexは、データ点をノードとする近傍グラフを構築し、検索時はある初期点からクエリ点に近い方向に探索していくことで、高速に検索を行うことができます。グラフベースindexに関する詳細はサーベイ論文などが参考になります。
SISAP Indexing Challengeの概要
今回参加したトラックであるTaskAでは、CLIPの埋め込みベクトルデータセットであるLAION5Bの画像埋め込みベクトルを対象とします。Recall@10 (Top-10の検索結果のうち厳密な近傍が含まれている割合)が0.9以上という制約の中で、より高速なアルゴリズムを提案することが目的です。
手法の概要
今回私たちは、既存のOff-the-shelfなグラフベースのindexに対して、3つの点: 1) 次元削減, 2) データベースのSubsampling, 3) Entry Pointの選択の統合的な最適化を行うことで、目的精度を達成しながらindex高速化する手法を提案しました。手法の全体像は下図に示されています。
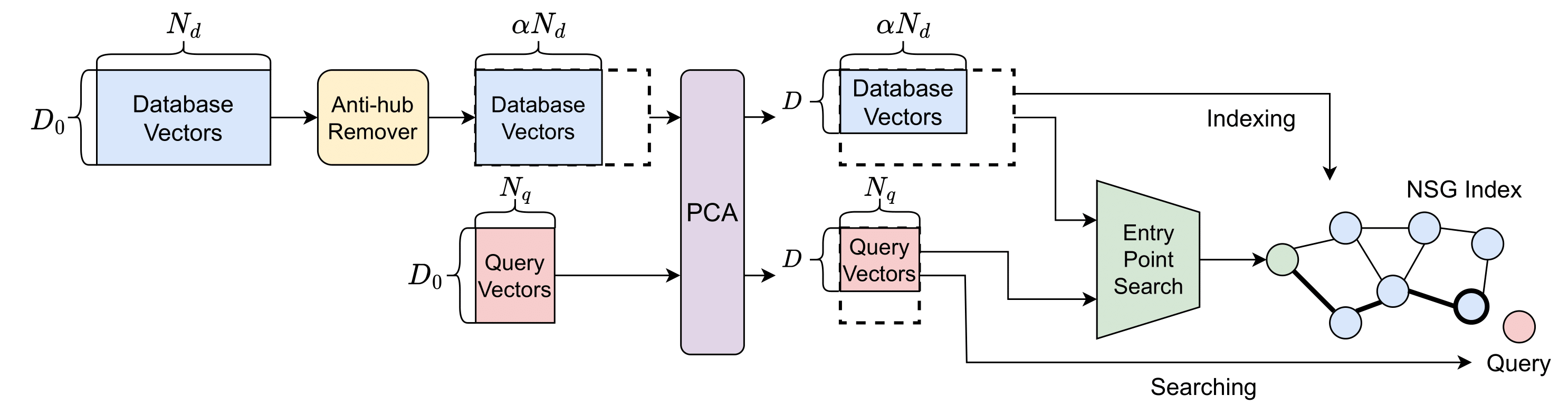
今回は具体的にグラフベースのindexの1つであるNSGというindexを対象にしました。NSGにおいてこれらの3つのパラメータが有効なパラメータであることを実験的に示した上で、これらのパラメータを統合的に最適化することで、高速なindexを構築することができました。
1. 次元削減
ベクトルの次元を削減することにより、検索の大部分を占める距離計算の高速化を図ります。今回はPCAを用いて次元削減を行いました。PCAは高速な実装がFaissにあり、それを簡単に利用することができます。
2. データベースのSubsampling
検索対象データを削減することで、検索で辿る必要のあるデータ点数が減少することが期待できます。もちろんただ単に減らせばいいというものではありません。できるだけ「不要そうな」データから除くことが望ましいでしょう。 そこで、Anti-hub Removalという手法を用いてsubsamplingを行いました。Anti-hub Removalは、hubnessの低いデータ点(anti-hub)はクエリに対する結果になりづらいという観測を元に、anti-hubを一定の割合で除去する手法です。Hubとは繋がっている辺の本数が平均よりもはるかに大きいノードです。hubnessはその度合いを測る指標です。 元論文ではメモリ使用量の削減を目的としていましたが、我々はこれが検索高速化にも有効であること、CLIP埋め込みという最新のデータセットでも有効であることを実験的に確認しました。
3. Entry Pointの選択
グラフ探索のentry point(初期点)をよりクエリに近い点にすることは、直接的に探索の高速化につながります。今回我々はk-meansを用いたシンプルなentry pointの選択方法を提案し、Faissを用いて実装しました。
事前に検索対象データ全体をk-meansによりクラスタリングし、各クラスタのセントロイドに最も近いデータ点たちをentry pointの候補とします。クエリ時にはentry pointの候補からクエリに最も近い点を選び、entry pointとします。
クエリのバッチ処理に関して、グラフのentry pointごとにクエリをグループ分けし、そのグループごとにバッチ処理で検索を行うことで、Faissの内部の並列性を犠牲にせずに実行することができます。これにより検索の速度を落とさずに、entry pointの変更を行うことができます。
epts = search_entry_points(queries) # in batch
for ep in np.unique(epts):
query_ids = (epts == ep)
query_batch = queries[query_ids, :]
index.set_entry_point(ep)
result[query_ids] = index.search(query_batch, k) # in batch
4. Optunaを用いたパラメータ最適化
これらを統合的に最適化するために、Optunaというブラックボックス最適化ライブラリを用いました。パラメータの最適化を行うことができます。今回はPCAの次元数、Subsamplingの割合、Entry Pointの選択におけるクラスタ数の3つのハイパーパラメータを最適化しました。 いくつかの定式化を試し、最も有効なものを選択しました。詳細は論文をご覧ください。
今回対象とした10M, 30Mスケールのindexの構築には数時間を要します。最適化の対象であるパラメータはindexの構築前に決まるものであるため、毎度のTrialでこの構築を行うことになり、現実的ではありません。そこで、パラメータ最適化に用いるデータベースの点数はそのSubset(300K)としました。このSubsetに対して最適化したパラメータをより大きいサイズのデータに対しても適用することで、パフォーマンスの向上を狙いました。実際にはパフォーマンスの要件を満たした上でより高い速度を達成するために、index構築後に調整可能なRuntime Parameterの最適化を行っています。
結果
最終的に、Faissに実装されているそのままのNSG (Vanilla NSG)、そしてBrute-forceに比べて表のようなパフォーマンスの改善が得られました。

コンペの感想
院試準備期間に重なる忙しい時期でしたが、最終的に満足のできる結果と、初めての主著論文が国際学会に採択されるという貴重な経験を得ることができました。参加してとてもよかったと感じています。 パラメータのチューニングというとエンジニアリングな要素が強いように感じていましたが、実際にやってみると課題が山盛りで、それを解決していく過程がとても楽しかったです。実際他のいくつかの研究でもチューニングについて論じられており、研究としても十分にやることがたくさんあるのだなという印象を受けました。 今回得られた成果と知識を今後の研究にも役立てていきたいです。 詳細が気になった方は是非論文をご覧ください。
Reference
図表は全て今回の論文から引用しています。
謝辞
本研究は、JST、AIP加速課題、JPMJCR23U2の支援を受けたものです。