SISAP 2023 Indexing Challenge Report
I’m Yutaro Oguri, a 4th-year undergrad in the Matsui Lab. We took part in a competition on Approximate Nearest Neighbor Search (ANNS) at SISAP 2023, a conference about similarity search. We got 2nd place in one of the tracks and also got a short paper accepted. This post is a summary of our work.
- Paper: Yutaro Oguri and Yusuke Matsui, “General and Practical Tuning Method for Off-the-Shelf Graph-Based Index: SISAP Indexing Challenge Report by Team UTokyo”
- Implementation: Submission by Team UTokyo
What is Approximate Nearest Neighbor Search?
ANNS helps find the closest match to a query vector from a set of vectors, quickly. Libraries like Faiss implement this. Nowadays, people use ANNS to search for documents converted into vectors by deep learning models or to support the retrieval in large language models. For the detailed tutorial in ANNS, please refer to CVPR 2023 tutorial by Yusuke Matsui.
Graph-based indexes we focused on perform better than other types of indexes as long as they fit in memory. These indexes build a neighborhood graph using data points as nodes. During a search, they move from an entry point toward the query point to find the result fast. For the details of graph-based indexes, please refer to the great survey paper.
About the SISAP Indexing Challenge
The task we participated in used CLIP embedding vectors from the LAION5B dataset. The goal was to create a fast algorithm with a Recall@10 rate of at least 0.9.
Our Approach
In this work, we propose a method to speed up existing off-the-shelf graph-based indexes by optimizing three aspects: 1) Dimension reduction, 2) Database subsampling, and 3) Entry point selection. The overall architecture of our method is shown in the diagram below.
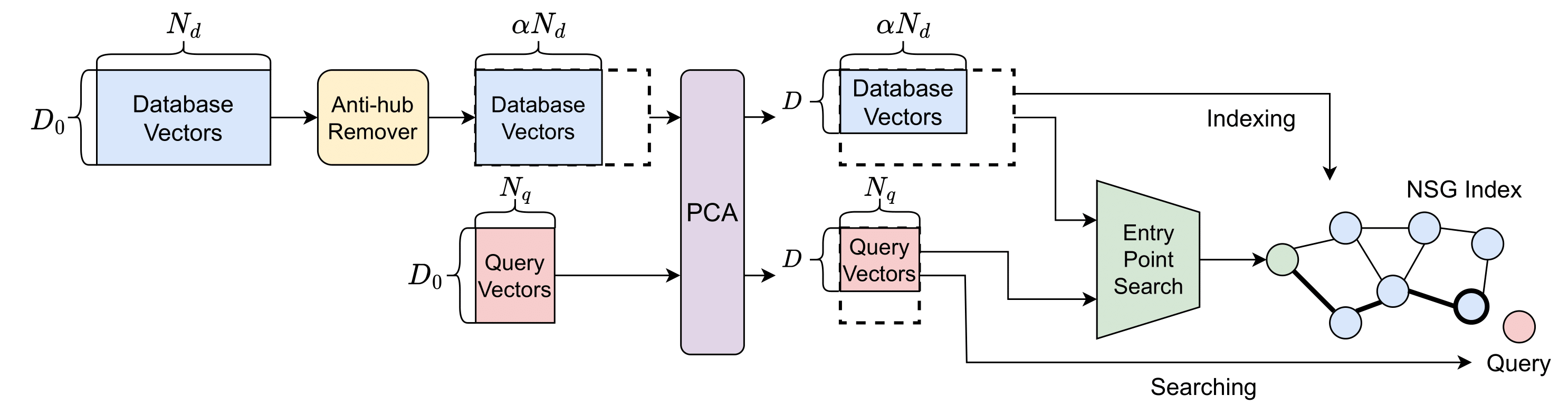
Specifically, we focused on one graph-based index called NSG. We experimentally demonstrated that these three parameters are effective in NSG. By optimizing these parameters in an integrated manner, we were able to construct a faster index.
1. Dimension Reduction
We reduced the dimensions of vectors to speed up distance calculations. We used PCA for this, which Faiss supports.
2. Database Subsampling
Reducing the search data means you have fewer points to go through during the search. We used a technique called Anti-hub Removal to remove less important points from the data.
3. Entry Point Selection
Choosing an entry point (initial point) in graph exploration that is closer to the query directly leads to faster search. In this work, we propose a simple method for selecting entry points using k-means clustering and implemented it using Faiss.
First, we divide the entire dataset to be searched into clusters using k-means. The data points closest to the centroid of each cluster serve as candidate entry points. During the query, we select the entry point that is closest to the query from among these candidates.
Regarding batch processing of queries, we group queries by their respective entry points in the graph. By performing searches in batches for each group, we can execute the search without sacrificing the internal parallelism of Faiss. This allows us to change the entry points without slowing down the search.
epts = search_entry_points(queries) # in batch
for ep in np.unique(epts):
query_ids = (epts == ep)
query_batch = queries[query_ids, :]
index.set_entry_point(ep)
# runs in batch
result[query_ids] = index.search(query_batch, k) # in batch
4. Parameter Tuning with Optuna
We used Optuna, a black-box optimization library, to fine-tune our method. We optimized three hyperparameters: the number of dimensions in PCA, the subsampling rate, and the number of clusters in k-means.
Results
Our method improved the performance compared to the basic NSG implemented in Faiss and brute-force searches.

Comments
Despite being busy with grad school exams, we are glad to participate it. We learned a lot, especially how much work goes into parameter tuning. It’s not just an engineering task; it has lots of research possibilities too. We want to use this experience in the future research.
If you’re interested, please check out our paper for details.
Reference
All figures and tables are cited from our paper.
Acknowledgements
This work was supported by JST AIP Acceleration Research JPMJCR23U2, Japan.